Cơ chế Global Interpreter Lock trong Python
Cơ chế quản lý bộ nhớ trong Python
Quản lý bộ nhớ là quy trình kiểm soát và phân phối tài nguyên bộ nhớ máy tính cho dữ liệu được sinh ra trong các chương trình đang chạy. Quản lý bộ nhớ trong một chương trình kết hợp hai nhiệm vụ liên quan, được gọi là cấp phát (allocation) và tái sử dụng (recycling).
Khi chương trình yêu cầu bộ nhớ, vì máy tính chỉ có bộ nhớ với dung lượng hữu hạn nên trình quản lý bộ nhớ phải tìm một số vùng trống trong bộ nhớ để có thể cung cấp cho chương trình. Quá trình cung cấp bộ nhớ này thường được gọi là cấp phát bộ nhớ. Ngược lại khi dữ liệu không còn cần thiết nữa thì nó có thể bị xóa đi hoặc giải phóng. Tác vụ này có thể được thực hiện thủ công bởi lập trình viên hoặc tự động bởi trình quản lý bộ nhớ.
Có một sự khác biệt đáng kể về mặt quản lý các đối tượng trong không gian bộ nhớ giữa ngôn ngữ lập trình Python và các ngôn ngữ lập trình khác. Tất cả các object trong Python đều được kế thừa từ PyObject chứa hai thông tin cơ bản:
- Py_REFCNT: chứa số lượng tham chiếu của đối tượng
- Py_TYPE: chứa con trỏ đến đối tượng loại tương ứng
Python cung cấp các module hỗ trợ cho cả xử lý đa luồng và xử lý đa tiến trình. Vấn đề là biến số tham chiếu cần được bảo vệ để tránh bị lỗi bởi các vấn đề race condition khi có hai hoặc nhiều luồng được thực thi đồng thời. Nếu biến số tham chiều này lỗi sẽ gây ra rò rỉ bộ nhớ hoặc bộ nhớ được giải phóng không chính xác. Một giải pháp cho vấn đề này là sử dụng một khóa chung duy nhất cho một luồng tương tác với tài nguyên được chia sẻ.
Giới thiệu về cơ chế Global Interpreter Lock
Trong ngôn ngữ lập trình Python tồn tại một cơ chế được gọi là Global Interpreter Lock (GIL). Cơ chế này khóa toàn bộ trình thông dịch, chỉ cho phép Python sử dụng một luồng duy nhất để thực thi các lệnh lập trình trong một chương trình. Điều này có nghĩa là trong Python tại một thời điểm chỉ có một luồng duy nhất được thực thi. Mỗi luồng muốn thực thi trước tiên phải đợi GIL được giải phóng bởi luồng đang thực thi. Python đã xuất hiện từ những ngày mà hệ điều hành không có khái niệm về luồng. Python được thiết kế để dễ sử dụng nhằm phát triển nhanh hơn và ngày càng có nhiều nhà phát triển bắt đầu sử dụng nó.
Rất nhiều tiện ích mở rộng đã được viết cho các thư viện C hiện có các tính năng cần thiết trong Python. Để ngăn các thay đổi không nhất quán, các phần mở rộng C này yêu cầu quản lý bộ nhớ an toàn theo luồng mà cơ chế GIL đã cung cấp. GIL rất dễ triển khai và được thêm vào Python. Nó gia tăng hiệu suất cho các chương trình đơn luồng vì chỉ cần quản lý một khóa. Các thư viện C không an toàn theo luồng đã trở nên dễ dàng tích hợp hơn. Những thành phần mở rộng bằng ngôn ngữ C này đã trở thành một trong những lý do khiến Python dễ dàng được các cộng đồng khác nhau chấp nhận.
Có thể hình dung đơn giản rằng GIL là microphone duy nhất trong một hội nghị chẳng hạn, bất kỳ ai muốn phát biểu đều phải nhận được microphone từ người đang giữ microphone ở thời điểm hiện tại. Do cơ chế GIL, hiệu suất của một chương trình đơn luồng và một chương trình đa luồng là tương đương nhau trong Python. Cơ chế này làm cho các chương trình đa luồng không tăng hiệu suất lên nhiều và thậm chí có thể làm giảm hiệu suất của một số chương trình đa luồng. Mình có viết thử một chương trình sau làm ví dụ minh họa cho vấn đề này:
import threading
import time
def loop_numbers(input_arr):
""" Thực thi tác vụ loop đơn giản trên input_arr
Args:
input_arr (iterable): input cần thực thi tác vụ loop
"""
for i in input_arr:
i = i
def run_multithreads(maximum_number, number_thread):
""" Thực thi loop_numbers với input trong khoảng từ 1 đến maximum_number
Chia đều kích thước input cho số lượng thread là number_thread để thực thi
Args:
maximum_data (int): Thực thi tác vụ loop_numbers từ 1 đến maximum_data trên nhiều threads
number_thread (int): số thread cần thực thi
"""
thread_list = list()
# Kích thước tối đa của input cho mỗi thread
batch_size = math.ceil(maximum_number/number_thread)
# Thực thi loop_numbers từ thread thứ 1 đến thread thứ number_thread
for thread_num in range(1, number_thread + 1):
# Điểm bắt đầu input cho thread thứ thread_num
number_start = (thread_num-1)*batch_size + 1
# Điểm kết thúc input cho thread thứ thread_num
number_end = min(thread_num*batch_size, maximum_number)
# Tạo input cần thực thi cho thread thứ thread_num
batch_input = range(number_start, number_end)
print(
f'Thread {thread_num}: Loop numbers from {number_start} to {number_end}')
t = threading.Thread(target=loop_numbers, args=[
batch_input]) # Gọi đến loop_numbers
t.start()
thread_list.append(t)
for _ in range(len(thread_list)):
t = thread_list[_]
t.join()
def main():
max_thread = 10
maximum_number = 10000000
for number_thread in range(1, max_thread + 1):
start = time.time()
run_multithreads(maximum_number, number_thread)
print(f'Using {number_thread} threads: {time.time() - start}s')
print('-----------------------------------')
if __name__ == "__main__":
main()Chúng ta sẽ thực thi tác vụ lặp từ 1 đến 10000000 cho 10 trường hợp cụ thể, lần lượt sử dụng từ 1 đến 10 thread khác nhau. Mỗi thread sẽ lặp trên một kích thước được chia đều cho mỗi thread. Dưới đây là output ghi lại thời gian thực thi lần lượt cho 10 trường hợp cụ thể.
Thread 1: Loop numbers from 1 to 10000000
Using 1 threads: 0.8599972724914551s
-----------------------------------
Thread 1: Loop numbers from 1 to 5000000
Thread 2: Loop numbers from 5000001 to 10000000
Using 2 threads: 0.9549980163574219s
-----------------------------------
Thread 1: Loop numbers from 1 to 3333334
Thread 2: Loop numbers from 3333335 to 6666668
Thread 3: Loop numbers from 6666669 to 10000000
Using 3 threads: 0.7449955940246582s
-----------------------------------
Thread 1: Loop numbers from 1 to 2500000
Thread 2: Loop numbers from 2500001 to 5000000
Thread 3: Loop numbers from 5000001 to 7500000
Thread 4: Loop numbers from 7500001 to 10000000
Using 4 threads: 0.7119965553283691s
-----------------------------------
Thread 1: Loop numbers from 1 to 2000000
Thread 2: Loop numbers from 2000001 to 4000000
Thread 3: Loop numbers from 4000001 to 6000000
Thread 4: Loop numbers from 6000001 to 8000000
Thread 5: Loop numbers from 8000001 to 10000000
Using 5 threads: 0.8559982776641846s
-----------------------------------
Thread 1: Loop numbers from 1 to 1666667
Thread 2: Loop numbers from 1666668 to 3333334
Thread 3: Loop numbers from 3333335 to 5000001
Thread 4: Loop numbers from 5000002 to 6666668
Thread 5: Loop numbers from 6666669 to 8333335
Thread 6: Loop numbers from 8333336 to 10000000
Using 6 threads: 0.8179986476898193s
-----------------------------------
Thread 1: Loop numbers from 1 to 1428572
Thread 2: Loop numbers from 1428573 to 2857144
Thread 3: Loop numbers from 2857145 to 4285716
Thread 4: Loop numbers from 4285717 to 5714288
Thread 5: Loop numbers from 5714289 to 7142860
Thread 6: Loop numbers from 7142861 to 8571432
Thread 7: Loop numbers from 8571433 to 10000000
Using 7 threads: 0.9519991874694824s
-----------------------------------
Thread 1: Loop numbers from 1 to 1250000
Thread 2: Loop numbers from 1250001 to 2500000
Thread 3: Loop numbers from 2500001 to 3750000
Thread 4: Loop numbers from 3750001 to 5000000
Thread 5: Loop numbers from 5000001 to 6250000
Thread 6: Loop numbers from 6250001 to 7500000
Thread 7: Loop numbers from 7500001 to 8750000
Thread 8: Loop numbers from 8750001 to 10000000
Using 8 threads: 0.9250006675720215s
-----------------------------------
Thread 1: Loop numbers from 1 to 1111112
Thread 2: Loop numbers from 1111113 to 2222224
Thread 3: Loop numbers from 2222225 to 3333336
Thread 4: Loop numbers from 3333337 to 4444448
Thread 5: Loop numbers from 4444449 to 5555560
Thread 6: Loop numbers from 5555561 to 6666672
Thread 7: Loop numbers from 6666673 to 7777784
Thread 8: Loop numbers from 7777785 to 8888896
Thread 9: Loop numbers from 8888897 to 10000000
Using 9 threads: 0.859999418258667s
-----------------------------------
Thread 1: Loop numbers from 1 to 1000000
Thread 2: Loop numbers from 1000001 to 2000000
Thread 3: Loop numbers from 2000001 to 3000000
Thread 4: Loop numbers from 3000001 to 4000000
Thread 5: Loop numbers from 4000001 to 5000000
Thread 6: Loop numbers from 5000001 to 6000000
Thread 7: Loop numbers from 6000001 to 7000000
Thread 8: Loop numbers from 7000001 to 8000000
Thread 9: Loop numbers from 8000001 to 9000000
Thread 10: Loop numbers from 9000001 to 10000000
Using 10 threads: 0.8629951477050781s
-----------------------------------Chúng ta có thể thấy trong 10 trường hợp sử dụng tối đa lần lượt từ 1 đến 10 thread khác nhau cùng thực thi tác vụ ban đầu, thời gian thực thi tác vụ vẫn là xấp xỉ nhau và không có bất kỳ trường hợp nào tăng hiệu suất lên đáng kể. Tác động của GIL không xảy ra trong chương trình đơn luồng, nhưng nó có thể gây ra hiện tượng bottleneck trong CPU-bound và trong các chương trình đa luồng.
Cơ chế GIL đối với I/O-bound và CPU-bound
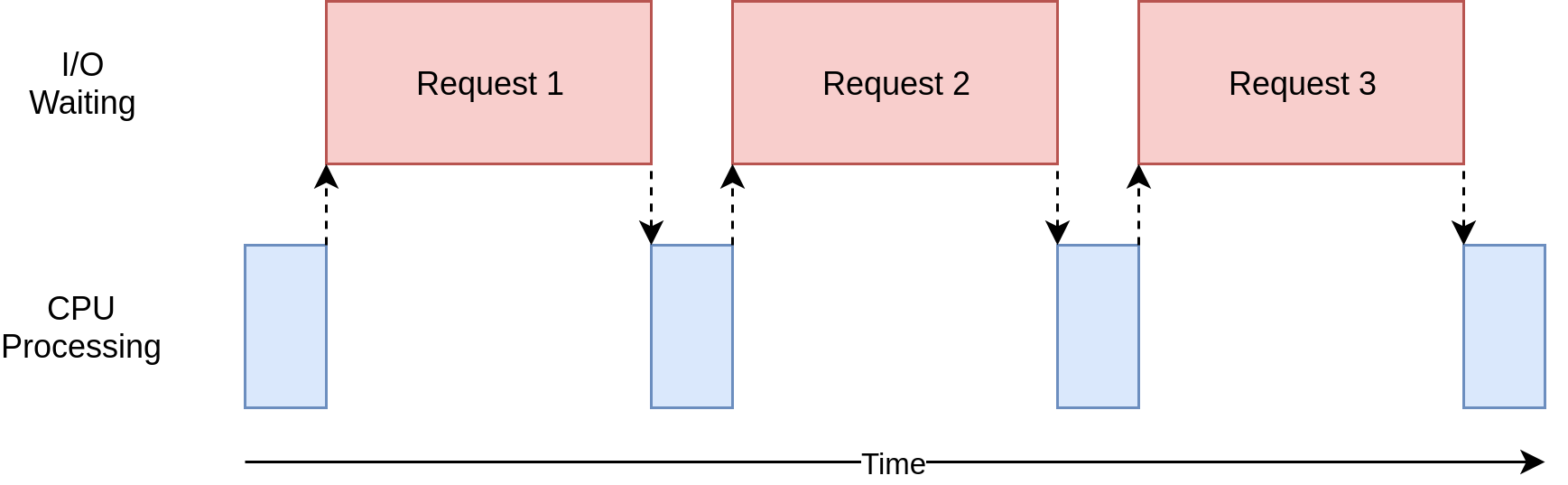
Trong ảnh minh họa trên, các ô màu xanh lam biểu diễn thời gian khi chương trình đang hoạt động và các ô màu đỏ biểu diễn thời gian chờ đợi tác vụ I/O hoàn tất. Tốc độ của chương trình bị giới hạn bởi phần lớp thời gian chờ đợi các tác vụ input/output được thực thi hoàn tất. Các tác vụ input/output này có thể là reading/writing dữ liệu từ ổ đĩa, reading/waiting dữ liệu từ bàn phím hoặc chuột máy tính, reading/waiting dữ liệu từ network,… . Có thể hiểu tổng quát các tác vụ input/output là tất cả những gì mà máy tính không thể tự thực hiện được và phải chờ đợi phản hồi từ những thành phần khác, ví dụ như trình duyệt trên máy tính chờ đợi dữ liệu phản hồi từ máy chủ.
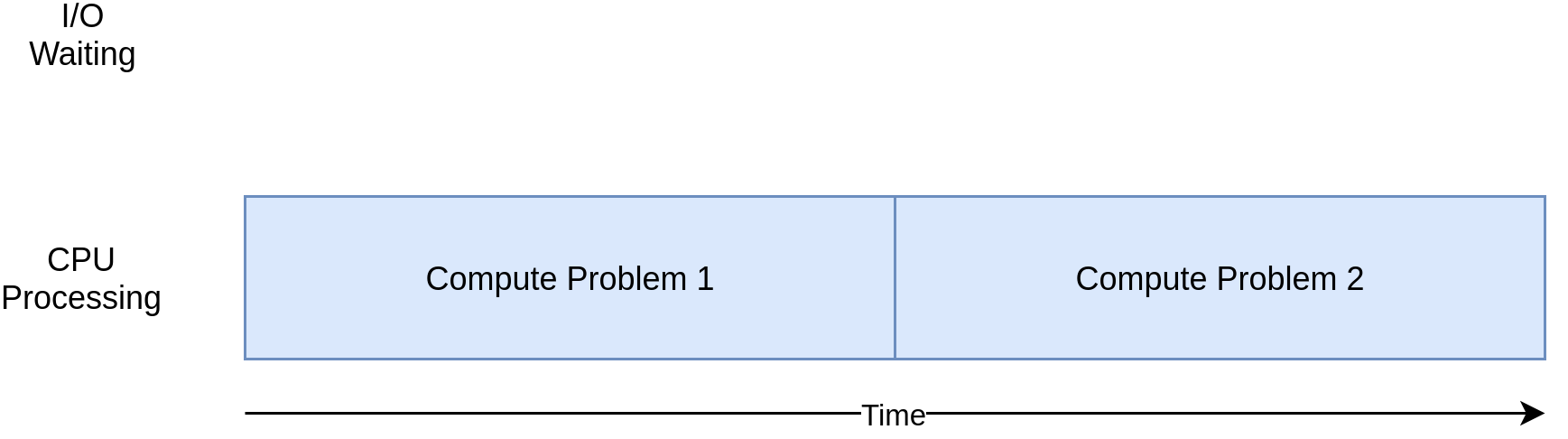
Mặt khác, có những chương trình thực hiện các tính toán mà không cần truy cập mạng hoặc truy cập những thành phần ngoại vi khác. Trong ảnh minh họa trên, chúng ta có thể thấy những tác vụ I/O không có bất kỳ ảnh hưởng đáng kể nào trong quá trình thực thi chương trình. Đây là những chương trình CPU-bound hay chương trình bị ràng buộc bởi CPU vì tài nguyên giới hạn tốc độ chương trình là CPU chứ không phải mạng hoặc những thành phần ngoại vi. Tóm lại thì CPU-bound là vấn đề tốc độ thực thi chương trình để hoàn thành một tác vụ chủ yếu được xác định và bị giới hạn bởi tốc độ của CPU. Việc tăng tốc những chương trình CPU-bound liên quan đến việc tìm kiếm phương thức để thực hiện nhiều phép tính toán hơn trong cùng một khoảng thời gian.
Có 3 hướng tiếp cận chính có thể sử dụng để giải quyết những vấn đề này mình đã tham khảo từ các nguồn khác nhau và được mô tả tóm gọn trong bảng bên dưới.
| Approach | Python package | Better | Parallel |
|---|---|---|---|
| Threading | threading | I/O-bound | No |
| Multiprocessing | multiprocessing | CPU-bound | Yes |
| Asynchronous | asyncio | I/O-bound | No |
Tài liệu tham khảo
- https://www.geeksforgeeks.org/what-is-the-python-global-interpreter-lock-gil
- https://www.javatpoint.com/python-memory-management
- https://www.guru99.com/python-multithreading-gil-example.html
- https://realpython.com/python-memory-management
- https://www.freecodecamp.org/news/multithreaded-python
- https://docs.python.org/3/c-api/structures.html
- https://realpython.com/python-concurrency
- https://granulate.io/introduction-to-the-infamous-python-gil
- https://www.programmersought.com/article/8984296557