Giải thích chi tiết về mô hình Sequence-to-Sequence
Giới thiệu
Mô hình Sequence-to-Sequence được đề xuất bởi Sutskever et al. vào năm 2014 và được sử dụng để tạo ra một chuỗi các token của câu trong ngôn ngữ đích \(y = \left\{ {{y_1},...,{y_m}} \right\}\) làm câu bản dịch tương ứng cho một chuỗi các token của câu trong ngôn ngữ nguồn \(x = \left\{ {{x_1},...,{x_n}} \right\}\) được cung cấp trước. Mục tiêu của quá trình huấn luyện là tối ưu hóa xác suất có điều kiện \(\begin{equation} {p\left( {{y_1},...,{y_m}|{x_1},...,{x_n}} \right)} \end{equation}\) với giá trị của \(m\) là độ dài của chuỗi đầu ra có thể khác với \(n\) là độ dài của chuỗi đầu vào. Mô hình này sử dụng kiến trúc Encoder-Decoder và thông thường thì mạng RNN hoặc những cải tiến như mạng LSTM và GRU sẽ được sử dụng cho cả bộ Encoder và bộ Decoder. Đặc biệt, mạng LSTM được sử dụng để giải quyết các vấn đề phụ thuộc dài, ghi nhớ và biểu diễn mối quan hệ của các thông tin phụ thuộc vào ngữ cảnh trong câu văn bản.
Mô hình Sequence-to-Sequence
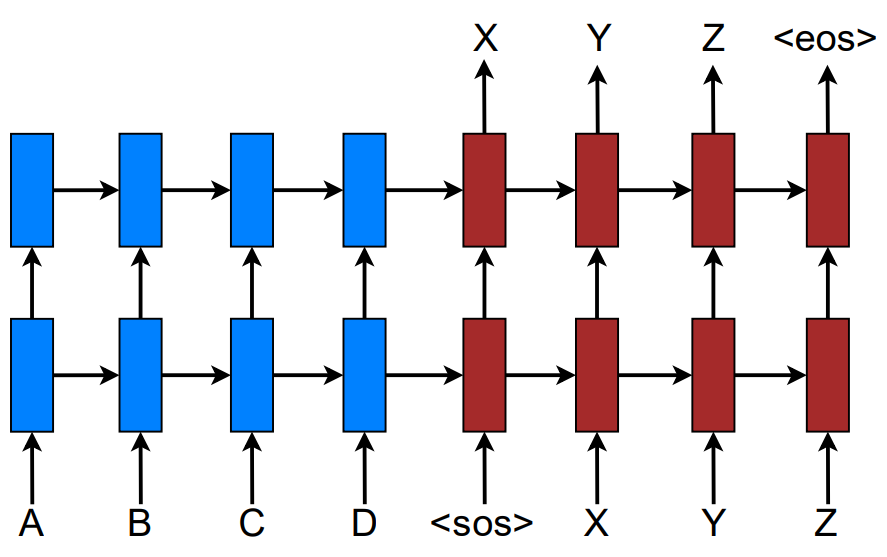
Các thành phần chính của mô hình Sequence-to-Sequence bao gồm:
- Bộ Encoder được sử dụng để ánh xạ chuỗi token trong ngôn ngữ nguồn đầu vào thành một vector có kích thước cố định. Tại mỗi bước mã hóa, Encoder sẽ nhận vector tương ứng với mỗi token trong chuỗi đầu vào để tạo ra vector trạng thái ẩn $s$ đại diện cho chuỗi đầu vào tại bước mã hóa cuối cùng.
- Bộ Decoder sử dụng vector $s$ như khởi tạo cho trạng thái ẩn đầu tiên và tạo ra chuỗi các token ở ngôn ngữ đích tại mỗi bước giải mã. Do đó, hàm xác suất có điều kiện có thể được phân tích như sau:
Trong vế phải của công thức trên, mỗi phân bố \(\begin{equation} {p\left( {{y_j}|s,{y_1},...,{y_{j - 1}}} \right)} \end{equation}\) mô tả xác suất xuất hiện của token \({y_j}\) với vector đại diện cho câu đầu vào \(s\) và các token trong chuỗi đầu ra đứng trước nó. Phân bố này được biểu diễn bằng một hàm \(\rm{softmax}\) trên tất cả token trong tập từ vựng ở ngôn ngữ đích.
Công thức trên có thể được viết lại thành dạng như sau:
\[\begin{equation} \text{log}p(y|x) = \sum_{j=1}^{m}\text{log}p(y_{j}|y_{<j},s) \end{equation}\]Mỗi token $y_{j}$ có xác suất xuất hiện được tính như sau:
\[\begin{equation} p(y_{j}|y_{j<s},s) = \text{softmax}(g(h_{j})) \end{equation}\]Trong đó $g$ là hàm dùng để biến đổi trạng thái ẩn $h_{j}$ của Decoder tại bước giải mã tương ứng thành vector có kích thước bằng kích thước của tập từ vựng trong ngôn ngữ đích. Trạng thái ẩn $h_{j}$ được tính như sau:
\[\begin{equation} h_{j} = f(h_{j-1},s) \end{equation}\]Trong đó $f$ là hàm biểu diễn chung cho quá trình tính trạng thái ẩn tại bước hiện tại từ trạng thái ẩn đầu ra của bước trước bằng mạng RNN hoặc bằng những cải tiến khác như LSTM và GRU. Trong mô hình của Sutskever et al., vector $s$ đại diện cho câu nguồn chỉ được sử dụng một lần để làm trạng thái ẩn đầu tiên cho bộ Decoder. Trong mô hình của tác giả Bahdanau et al. và của tác giả Luong et al., $s$ là một vector đặc biệt được sử dụng xuyên suốt tại mỗi bước trong quá trình giải mã.
Hàm mất mát cần tối ưu hóa trong quá trình huấn luyện là một hàm có dạng tích của các hàm cross-entropy:
\[\begin{equation} L = - \sum\limits_{j = 1}^m {\sum\limits_{i = 1}^V {{q_{j,i}}\log \left( {{p_{j,i}}} \right)}} \end{equation}\]Trong đó, $q_{j,i}$ là phần tử thứ $i$ của vector one-hot $q_{j}$ có kích thước $V$ tại bước giải mã thứ $j$. Vector $q_{j}$ biểu diễn cho token thứ $j$ trong chuỗi token nhãn đầu ra từ tập huấn luyện. $p_{j,i}$ là phần tử thứ $i$ của vector $p_{j}$ cũng có kích thước $V$ với \({p_j} = {\text{softmax}}\left( {g\left( {{h_j}} \right)} \right)\).
Về cơ bản sau khi quá trình huấn luyện hoàn tất, chúng ta sẽ tạo ra bản dịch $\widehat y$ từ một chuỗi đầu vào $\widehat x$ chưa biết trước bằng cách tính toán sinh ra bản dịch có khả năng xuất hiện cao nhất dựa vào mô hình thu được sau khi huấn luyện:
\[\begin{equation} \widehat y = \mathop {{\text{argmax}}}\limits_y \left( {p\left( {y|\widehat x} \right)} \right) \end{equation}\]Cơ chế giải mã với thuật toán Greedy Search
Trong quá trình giải mã của mô hình Sequence-to-Sequence, thuật toán Greedy Search là một giải pháp đơn giản để mô hình dự đoán phần tử của chuỗi đầu ra tại mỗi bước của quá trình giải mã. Ở mỗi bước thời gian, trạng thái ẩn ở mạng RNN của bộ Decoder sẽ được ánh xạ thành một vector có kích thước $V$ bằng với kích thước của tập từ vựng ở ngôn ngữ đích. Hàm sofmax sẽ chuẩn hóa vector này thành vector $p$ với mỗi phần tử là giá trị xác suất xuất hiện của mỗi token tương ứng trong tập từ vựng ở ngôn ngữ đích với chuỗi đầu vào cho trước và chuỗi các phần tử đã được giải mã tại các bước trước. Hàm \({\rm{argmax}}\) sẽ tính ra vị trí của phần tử trong vector $p$ có xác suất cao nhất và chúng ta sẽ chọn ra được token có vị trí tương đương với giá trị này trong tập từ vựng ở ngôn ngữ đích. Quá trình giải mã dừng lại khi trong chuỗi đầu ra xuất hiện token đặc biệt “\(<EOS>\)”.
Cơ chế giải mã với thuật toán Beam Search
Một vấn đề khi mô hình Sequence-to-Sequence áp dụng thuật toán Greedy Search trong quá trình giải mã là nếu những phần tử đầu tiên trong chuỗi đầu ra được dự đoán thiếu chính xác, chất lượng toàn chuỗi đầu ra sẽ bị ảnh hưởng nghiêm trọng do quá trình giải mã tạo các phần tử tiếp theo trong chuỗi đầu ra đều được tính toán dựa trên các phần tử đầu tiên. Với thuật toán Beam Search, thay vì chỉ chọn ra một phần tử duy nhất có xác suất cao nhất tại mỗi bước giải mã, chúng ta sẽ giữ lại $k$ giả thuyết có xác suất cao nhất cho các bước giải mã tiếp theo với $k$ là tham số chiều rộng (beam width). Khi token đặc biệt “\(<EOS>\)” xuất hiện trong mọi giả thuyết, chúng ta kết thúc quá trình giải mã và chọn ra giả thuyết có giá trị xác suất \(p\left( {{y_1},{y_2},...,{y_{ < EOS > }}|{x_1},{x_2},...,{x_n}} \right)\) cao nhất làm kết quả cuối cùng cho chuỗi đầu ra. Ý tưởng này khắc phục được vấn đề khi mô hình Sequence-to-Sequence áp dụng thuật toán Greedy Search cho quá trình giải mã, cho phép quá trình giải mã có thể tạo được chuỗi đầu ra có chất lượng tốt hơn nếu như những phần tử đầu tiên của chuỗi đầu ra thiếu chính xác.